Katib
I think I have explored enough the hyper-parameters tuning tools: to conclude this series I had a look at Katib because it fits well the environment I can use at work. This time I did not have fun looking at strange algorithms, as Katib is just a shell that allows you to run comfortably optimization tools in Kubernetes. By chance I saw in Google that Katib, or better Kātib, was a writer, scribe, or secretary in the Arabic-speaking world (Wikipedia): indeed the tool keep tracks of optimization results, schedules new executions and provide an UI, a good secretary job.
This paper describes Katib:
A Scalable and Cloud-Native Hyperparameter Tuning System. Johnu George, Ce Gao, Richard Liu, Hou Gang Liu, Yuan Tang, Ramdoot Pydipaty, Amit Kumar Saha. arXiv:2006.02085v2 [cs.DC] 8 Jun 2020
link: https://arxiv.org/abs/2006.02085
The authors are from Cisco, Google, IBM, Caicloud, and Ant Financial Services.
Katib is part of Kubeflow, a Kubernetes platform to industrialize working on machine learning. Katib does not offer you a specific algorithm to optimize parameters, it is instead a shell allowing you to run in a reliable way other tools. From the article introduction you get that: you must be familiar with Kubernetes, you can run it on your laptop but in the end is done to run on a Kubernetes cluster, it is open source, and it is thought also for operation guys.
As it is built on top of Kubernetes, you can have one cluster with many namespaces into it, and segregate each team work into a different namespace. You can leverage Kube role management, to configure the permissions to access these namespaces. Katib provides logging an monitoring to get insight in what it is going on during the simulations.
As many other Kube tools, you configure your experiments with yaml resources. These resources are fetched from some controllers that update theirs states and tries to fulfill what you are asking for. this is the example reported in the paper:

The parallelTrialCount allow to specify how many processes to run in parallel, to limit the resources used by a team. As you can imagine, scalability is not an issues as all works the cloud way. The authors say they used chaos-engineering tools to stress Katib and verify that it is robust enough to be user in real applications.
This is a reporting view on trial results:
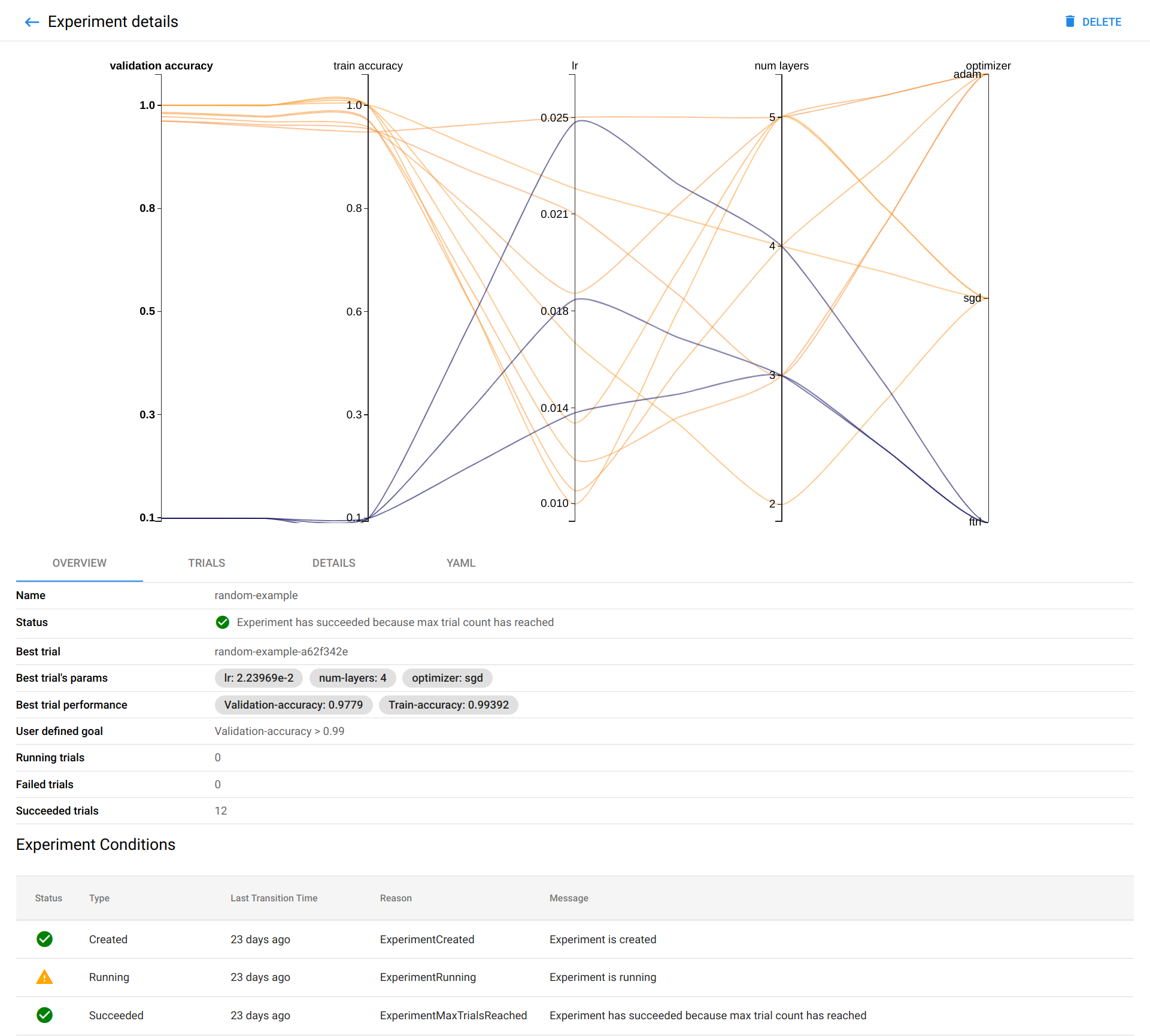
The leftmost axis, called validation accuracy, is the target function to optimize – here the higher the better. Following the orange lines on the other axis you can see which have been the hyper-parameters values that have given the better results. For instance here seems it is better to have the learning rate between 0.01 and 0.018.
And that’s all I had to say.

Leave a comment